

This is a two parts blog series: Part 1 is focused on a simple command to export/import data, while Part 2 handles with more advanced use cases.
Limitations
Having an easy to use command to export/import data is nice, but at some point you may be stuck with more complex use cases.
This happened to me with a quite basic one though. The command described in the first part of this blog post series (see here if you haven’t read it) was intended to be as easy to use as possible. But what if you need to handle a relationship between the same sObject ? For instance Account and Parent Account. Well, it just doesn’t work.
We started to use the command on several projects (including moving data for Salesforce CPQ / Billing), and it quickly became obvious that even though the command was easy to use, it had too many limitations :
- No way to handle relationships on the same sObjects (Account/Parent Account).
- No way to exclude fields (for instance a source org had audit fields writeable, whereas the target org did not, so we wanted to remove CreatedDate, LastModifiedDate, etc…).
- No way to update records previously inserted (if you have circular dependencies, you may need to first create a record and update later once some other related records are created).
- No way to filter the records you want to export.
Again, this was something intended at the beginning, as the main point of the command was to be as easy as possible. There are already lots of powerful data loading tools out there that can do whatever you want, and the point wasn’t to replace them.
Still, there was room for improvement.
A more powerful command
So how should we add these features to the existing command ?
Exporting a few sObjects looks like this :
sfdx texei:data:export —-objects Account,Contact,Opportunity,MyCustomObject__c --outputdir ./data
Obviously, if we wanted to add filters to each exported sObjects, that would quickly become a giant command to run, and a not very scalable one if we need to add more options (like fields we want to exclude).
We choose in this case to rely on a data plan file, that would describe what we want to export, with every options for every sObjects. The other good thing with using a file is that it makes it easy to export data again with all the same options.
Let’s generate a sample data plan file by running the following command :
sfdx texei:data:plan:generate --objects Account,Contact,MyCustomObject__c --outputdir ./data
This will generate the following data-plan.json file for you (provided that the data folder already exists) :
Then you can fill in all options :
excludedFields: a list of fields to exclude. Either at sObject level, or at root level where it will exclude fields for all sObjects.name: the developer name of the sObject to export. This is the only mandatory field.label: a label that will be used for the file, useful if you’re exporting the same sObject several time.filters: a filter that will get added to a where clause.
Each sObject will be exported and imported in the order coming from the json file, meaning you’ll need the parent sObjects to be listed first, otherwise hierarchy won’t be exported/imported correctly.
Managing relationship between the same sObject
With a single level of hierarchy
Let’s take a basic Account/Parent Account relationship, you could simply run the following :
sfdx texei:data:plan:generate --objects Account,Account --outputdir ./data
Here, Account is exported twice, because we first want to export the parents, and then the children. This way parents will be inserted first, the command will bring the Ids back from the insert, and the relationship will be replaced on the fly while inserting child accounts. Your data plan would just need to filter the ParentId accordingly :
Running the sfdx texei:data:export command with this data plan would just :
- Export all accounts without a parent (
ParentId = null). - Export all accounts with a parent (
ParentId != null).
Then running the sfdx texei:data:import command would:
- Import the parents first (because it’s the first exported sObject).
- Import the child, making sure that parents are already imported.
Doing it the other way round would just insert the child sObjects with the ParentId lookup empty, because the relationship couldn’t be resolved (Parent wouldn’t be imported at this time).
This works fine when you have only one level of parents, but what if you have 3 or 4 levels ?
All children would be part of the 2nd export, and may not be inserted in the correct order. Let’s look at a better way to do it.
With multiple levels of hierarchy
To manage multiple levels of hierarchy, you could try to separate all parents and child in multiple files with different filters, but that would quickly become painful.
Another option is to export all records first, without the relationship field (so that all records will get created and will have an id), and then update them with the relationship field. The command will take care of inserting or updating, depending on whether the record was already created in a previous step or not.
Looking at this file :
Here you’re just exporting/importing all the accounts twice, so you’ll get the exact same data in both exported files. During import, you won’t get any duplicate, the second import will just update the records inserted previously. In this specific case it doesn’t make sense as data will be the same.
But let’s look at this file :
Here the command will :
- Export/import all accounts with all fields, excluding the ParentId field.
- Export/import all accounts again, with the relationship field (ParentId).
This way you’ll get all accounts inserted first, with ParentId empty. And then all same accounts will get updated with the relationship. As all accounts will be inserted in the first batch, you then don’t care about the number of levels in the relationship, all accounts will be there.
Is it the most efficient ? Maybe not. Is it the easiest ? I think so, as you don’t have to manage as many exports and filtering as the number of levels you have.
Again, there are lots of powerful tools to manage millions of records insertion. This tool is focused on easily retrieving and inserting data for your dev environment. Once a data plan is created, it’s very easy to “refresh” the data as you’ll just have to run the export command once again.
A more complex example
Let’s say we have the following data model :
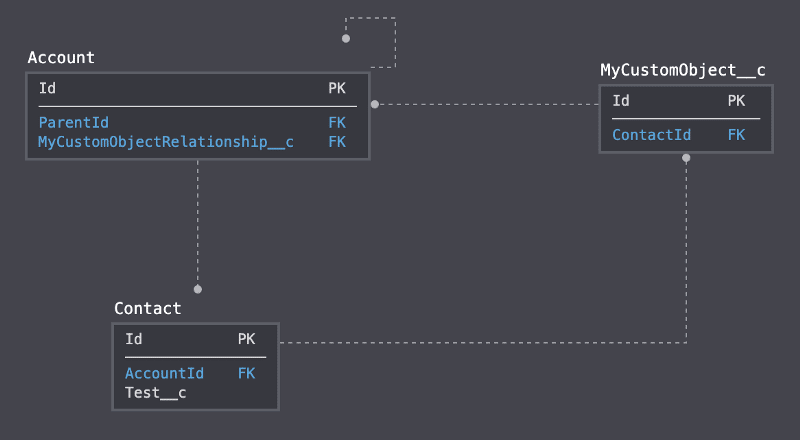
Said with words, you have :
- Account and Parent Account.
- Contact, with a standard lookup to Account, and a
Test__cfield that we don’t want to retrieve (maybe we’re retrieving data from a sandbox with some tests made on it). - A Custom Object having a lookup to Contact.
- Account, having itself a lookup to the Custom Object.
To be able to export and import these sObjects, your data-plan.json file would look like this :
The root excludedFields is not mandatory. The command will query the schema to retrieve all createable fields so you shouldn’t bother. But as I said previously I had a use case with a source org that had audit fields writeable and target org didn’t. So this is just the way you can make it work easily.
You can then import the exported data with just one command line :
sfdx texei:data:import --inputdir ./dataAnd that’s it !
One specific word : Standard Pricebook
Standard Pricebook is a little bit tricky, because :
- All Products having a Pricebook Entry linked to any custom Pricebook must also have a Pricebook Entry linked to the Standard Pricebook.
So you must import Pricebook Entries linked to the Standard Pricebook first.
- Standard Pricebook is part of the org, it can’t be created or replaced by any other Pricebook.
It’s fine in a sandbox to sandbox scenario where it will likely have the same id in all sandboxes. However in a Scratch Org, the Pricebook Id will be different for every org. The command will handle this use case for you, querying the Standard Pricebook Id for you a replacing it on the fly while importing records.
For this use case, the following data-plan.json file should do the job :
This data plan will :
- Export/import the Pricebooks (taking care of the Standard Pricebook).
- Export/import all Products.
- Export/import Pricebook entries linked to the standard Pricebook first.
- Finally, export/import Pricebook entries linked to a custom Pricebook (which wouldn’t work without the standard ones being inserted first, which is why we have 2 separate PricebookEntry sections with specific filters: to import and export them in 2 times).
That’s it ! This command solved all our use cases so far, let us know how it goes for you !
I would like to thank Christian Szandor Knapp for proofreading this article, and Audrey Riffaud for fixing my english 😄






